Agile delivery of data science projects
Author: Michele Usuelli, Principal Data Scientist, Microsoft
Objectives
Delivering a data science project, some common challenges are:
- lack of clear goals: data science experimentation done in isolation with unclear business value
- lack of quick results: inconsistent direction not leading to any results
- lack of quality: lack of the technical quality to put the work into production
If you relate to either of these challenges, this article is for you. It will highlight some lessons learned from my projects at Microsoft on how to tackle these problems.
This article shows a delivery methodology which objectives are:
- clarity: map high-level business requirements to low-level technical capabilities
- velocity: deliver the project quickly and in small increments, heading towards a consistent goal
- quality: ensure that the product meets the quality standards
The next sections describe the different components of a proposed solution to these problems.
Personas
Working on a data science project, the starting point is to define the personas involved.
The key personas are the individuals most affected by a data science project:
- end user: the person on the field whose action that ultimately drives the value
- product owner: prioritize work as per the business value, managing the stakeholders
- subject-matter experts: provide data and input to data scientists
In the deliver team, the three key technical roles are:
- data scientist: conducts analytical experiments
- data engineer: turns the data science experimentation into a tool
- solution architect: designs the broader technical infrastructure
Project set-up
The project step can usual be divided into 3 phases:
- Business discovery: understand how to drive a business outcome, usually triggering an action
- Analytical discovery: identify the data required to achieve the goal
- Technical discovery: choose the software required to achieve the goal
The outcome of the project set-up is
- A document describing the vision and objectives
- An initial list of data science activities together with an assessment of their complexity
Project delivery
After the project is set, the delivery process can be based on the Microsoft TDSP (Team Data Science Process) or on similar methodologies.
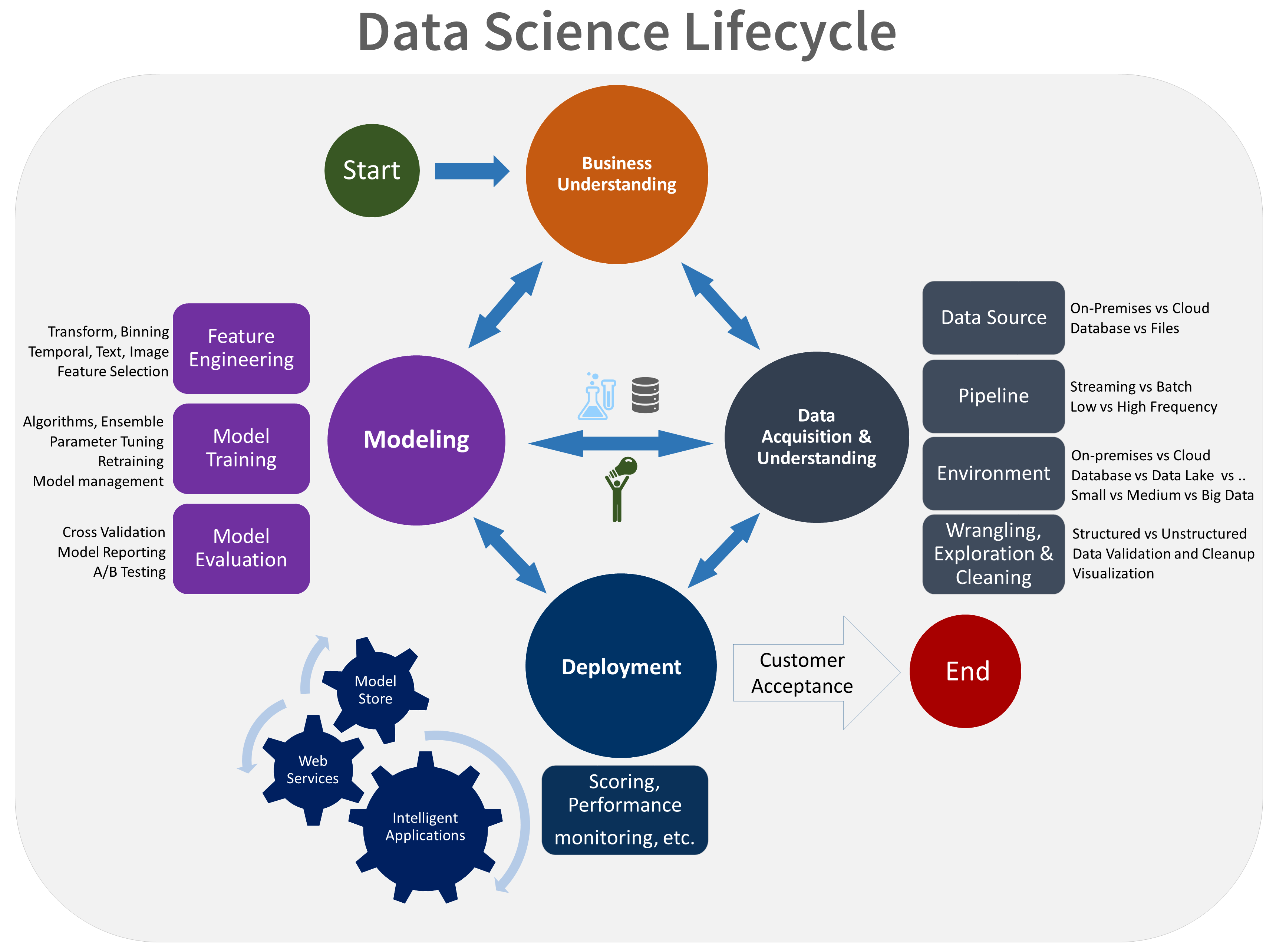
The TDSP is compatible with the agile delivery methodology.
Per agile project delivery, each piece of work is described by a user stories to be delivered in 2-3 weeks:
- persona: end user getting a benefit from the outcome of the work
- value: benefit that the end user is getting
- outcome: criteria to consider the activity completed
Specifically, there are usually three key categories user stories related to data science work
- data wrangling: collect the data required
- Persona: data scientist
- Value: data scientist
- Outcome: dataset ready to be used
- exploratory data analysis: analyze the data to understand how to use it
- Persona: data scientist
- Value: clarity about what to do with the data
- Outcome: list of data science choices, data-driven report explaining the reason from the choices
- data modelling: build a machine learning model
- Persona: data engineer
- Value: capability to deploy the data science work as a tool
- Outcome: production level code preparing and utilizing the predictive model
Ultimately, the tool automatically runs the machine learning model and advising the end user about the action to take.
To facilitate the delivery, it is worth defining
- a technical quality checklist for each type of user story, to ensure consistency
- actors and a detail delivery process for each type of user story, to speed-up the delivery
Conclusions
This delivery methodology enabled
- clarity: each piece of work has a target persona and value
- velocity: each piece of work gets delivered in 2-3 weeks
- quality: each piece of work complies with pre-defined quality standards
If you relate with this article, please think about how it can apply to your day-to-day job. If you have any feedback or suggestions, please reach out to me.